



In the next set of topics we will dive into different approachs to solve the hello world problem of the NLP world, the sentiment analysis . Sentiment analysis is an area of research that aims to tell if the sentiment of a portion of text is positive or negative.
Check the other parts: Part1 Part2 Part3
The code for this implementation is at https://github.com/iolucas/nlpython/blob/master/blog/sentiment-analysis-analysis/naive-bayes.ipynb
The Naive Bayes classifier
The Naive Bayes classifier uses the Bayes Theorem, that for our problem says that the probability of the label (positive or negative) for the given text is equal to the probability of we find this text given the label, times the probability a label occurs, everything divided by the probability of we find this text:
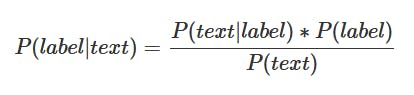
Since the text is composed of words, we can say:
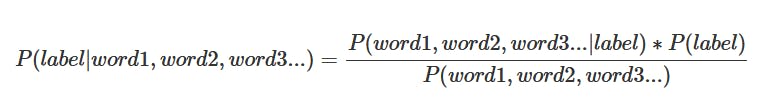
We want to compare the probabilities of the labels and choose the one with higher probability. Since the term P(word1, word2, word3…) is equal for everything, we can remove it. Assuming that there is no dependencebetween words in the text (which can cause some errors, because some words only “work” together with others), we have:
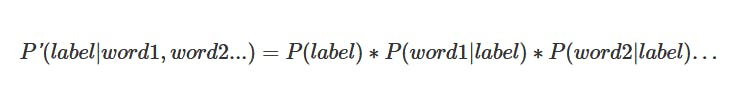
So we are done! With a training set we can find every term of the equation, for example:
- P(label=positive) is the fraction of the training set that is a positive text;
- P(word1|label=negative) is the number of times the word1 appears in a negative text divided by the number of times the word1 appears in every text.
The Code
For this task we will use a famous open source machine learning library, the scikit-learn .
Our dataset is composed of movie reviews and labels telling whether the review is negative or positive. Let’s load the dataset:
The reviews file is a little big, so it is in zip format. Let’s Extract it:
import zipfile
with zipfile.ZipFile("reviews.zip", 'r') as zip_ref:
zip_ref.extractall(".")
Now that we have the reviews.txt and labels.txt files, we load them to the memory:
with open("reviews.txt") as f:
reviews = f.read().split("\n")
with open("labels.txt") as f:
labels = f.read().split("\n")
reviews_tokens = [review.split() for review in reviews]
Next we load the module to transform our review inputs into binary vectors with the help of the class MultiLabelBinarizer :
from sklearn.preprocessing import MultiLabelBinarizer
onehot_enc = MultiLabelBinarizer()
onehot_enc.fit(reviews_tokens)
After that we split the data into training and test set with the train_test_split function:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(reviews_tokens, labels, test_size=0.25, random_state=None)
Next, we create a Naive Bayes classifier and train our data. We will use a Bernoulli Naive Bayes classifier that is appropriate for feature vectors composed of binary data. We do this with the class BernoulliNB :
from sklearn.naive_bayes import BernoulliNB
bnbc = BernoulliNB(binarize=None)
bnbc.fit(onehot_enc.transform(X_train), y_train)
Training the model took about 1 second only!
After training, we use the score function to check the performance of the classifier:
score = bnbc.score(onehot_enc.transform(X_test), y_test)
Computing the score took about 0.4 seconds only!
Running the classifier a few times we get around 85% of accuracy. Not so bad for a so simple classifier.
If you have any questions or comments, please leave them below!