




We will implement the skipgram model with pytorch.
Here is a great resource for understanding the skip gram model.
We will divide this post into three parts:
- Loading and preparing dataset
- Creating dataset tuples
- Creating model
- Training it
1. Loading and preparing dataset
For our task in creating word vectors we will use the movie plot description of wikipedia, available at https://www.kaggle.com/jrobischon/wikipedia-movie-plots . We will use the following code:
from string import punctuation
import pandas as pd
df = pd.read_csv("data/wiki_movie_plots_deduped.csv")
clear_punct_regex = "[" + punctuation + "\d\r\n]"
corpus = df['Plot'].str.replace(clear_punct_regex, "").str.lower()
corpus = " ".join(corpus)
open("corpus2.txt", "w", encoding="utf8").write(corpus)
First we import pandas for parsing the csv file and them the punctuation variable that olds common punctuations used in strings.
>> punctuation
'!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~'
Line 4 we load the data of movie plot; line 5 we build the regex string used for remove punctuations from the text as well as control the characters: \n (new line), \r (also used for new line) and \d (any digits, 1 2 3 etc); line 6 we apply the regex string replacing every match with an empty string; line 7 we join all the rows of the movie plots strings into an unique long row; line 8 we write this cleaned long row of movie plots in a .txt file
We are done with data loading and cleaning.
2. Creating data tuples
corpus = open("data/corpus.txt", encoding="utf8").readlines()
corpus = " ".join(corpus).replace("\n", "")
corpus = corpus.split(" ")
After creating the corpus file, we load it and remove line termination symbols from it (\n). We then split it into a tokens list.
from collections import Counter
vocab_cnt = Counter()
vocab_cnt.update(corpus)
vocab_cnt = Counter({w:c for w,c in vocab_cnt.items() if c > 5})
Next we count the number of ocurrences of each word and remove those that ocurrs less than 5 times.
import numpy as np
import random
vocab = set()
unigram_dist = list()
word2id = dict()
for i, (w, c) in enumerate(vocab_cnt.most_common()):
vocab.add(w)
unigram_dist.append(c)
word2id[w] = i
unigram_dist = np.array(unigram_dist)
word_freq = unigram_dist / unigram_dist.sum()
#Generate word frequencies to use with negative sampling
w_freq_neg_samp = unigram_dist ** 0.75
w_freq_neg_samp /= w_freq_neg_samp.sum() #normalize
#Get words drop prob
w_drop_p = 1 - np.sqrt(0.00001/word_freq)
#Generate train corpus dropping common words
train_corpus = [w for w in corpus if w in vocab and random.random() > w_drop_p[word2id[w]]]
In the above code we do several things:
- Create a vocab variable to stores all the words that appears in our corpus;
- Create a unigram_dist var to accumulate the number of occurrences of each word;
- Create a word2id dict that will help us encoding our words into values;
- Create w_freq_neg_samp, a probability distribution for sampling words in the negative sampling step;
- Create w_drop_p, a probability distribution for sampling words that will be in our training data;
- Create our training data, discarding some words based on w_drop_p.
import torch
#Generate dataset
dataset = list()
window_size = 5
for i, w in enumerate(train_corpus):
window_start = max(i - window_size, 0)
window_end = i + window_size
for c in train_corpus[window_start:window_end]:
if c != w:
dataset.append((word2id[w], word2id[c]))
dataset = torch.LongTensor(dataset)
if USE_CUDA:
dataset = dataset.cuda()
In the above snippet we create the tuples of word and context word that will be used for training our model. We convert them in torch tensors and attach to gpus if they are available.
3. Creating the model
import torch
from torch import nn, optim
import torch.nn.functional as F
VOCAB_SIZE = len(word2id)
EMBED_DIM = 128
class Word2Vec(nn.Module):
def __init__(self, vocabulary_size, embedding_dimension, sparse_grad=False):
super(Word2Vec, self).__init__()
self.embed_in = nn.Embedding(vocabulary_size, embedding_dimension, sparse=sparse_grad)
self.embed_out = nn.Embedding(vocabulary_size, embedding_dimension, sparse=sparse_grad)
#Sparse gradients do not work with momentum
self.embed_in.weight.data.uniform_(-1, 1)
self.embed_out.weight.data.uniform_(-1, 1)
def neg_samp_loss(self, in_idx, pos_out_idx, neg_out_idxs):
emb_in = self.embed_in(in_idx)
emb_out = self.embed_out(pos_out_idx)
pos_loss = torch.mul(emb_in, emb_out) #Perform dot product between the two embeddings by element-wise mult
pos_loss = torch.sum(pos_loss, dim=1) #and sum the row values
pos_loss = F.logsigmoid(pos_loss)
neg_emb_out = self.embed_out(neg_out_idxs)
#Here we must expand dimension for the input embedding in order to perform a matrix-matrix multiplication
#with the negative embeddings
neg_loss = torch.bmm(-neg_emb_out, emb_in.unsqueeze(2)).squeeze()
neg_loss = F.logsigmoid(neg_loss)
neg_loss = torch.sum(neg_loss, dim=1)
total_loss = torch.mean(pos_loss + neg_loss)
return -total_loss
def forward(self, indices):
return self.embed_in(indices)
w2v = Word2Vec(VOCAB_SIZE, EMBED_DIM, False)
if USE_CUDA:
w2v.cuda()
In the above class, we define our pytorch model. It is composed by two lookup embedding tables with uniform weight initialization.
To train our embeddings we are going to use Negative Sampling. In the function neg_samp_loss we compute the following quantity:
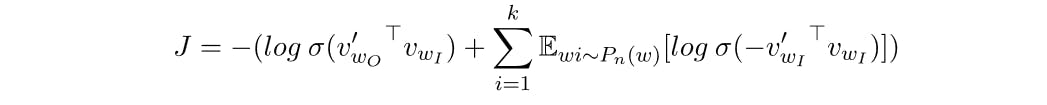
The first term
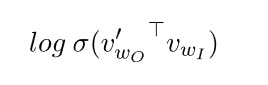
we compute between the lines 23 and 26; The second term
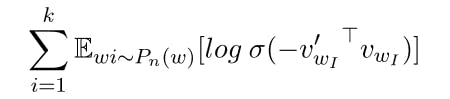
we compute between lines 28 and 33.
def get_negative_samples(batch_size, n_samples):
neg_samples = np.random.choice(len(vocab), size=(batch_size, n_samples), replace=False, p=w_freq_neg_samp)
if USE_CUDA:
return torch.LongTensor(neg_samples).cuda()
return torch.LongTensor(neg_samples)
Here we define our function to generate negative targets to be used in our objective during training.
optimizer = optim.Adam(w2v.parameters(), lr=0.003)
Here we just define the optimizer that will perform our weight updates.
4. Training the model
def get_batches(dataset, batch_size):
for i in range(0, len(dataset), batch_size):
yield dataset[i:i+batch_size]
This function is used for generate our batches during the training loop.
n_epochs = 5
n_neg_samples = 5
batch_size = 512
for epoch in range(n_epochs): # loop over the dataset multiple times
loss_values = []
start_t = time.time()
for dp in get_batches(dataset, batch_size):
optimizer.zero_grad() # zero the parameter gradients
inputs, labels = dp[:,0], dp[:,1]
loss = w2v.neg_samp_loss(inputs, labels, get_negative_samples(len(inputs), n_neg_samples))
loss.backward()
optimizer.step()
loss_values.append(loss.item())
ellapsed_t = time.time() - start_t
#if epoch % 1 == 0:
print("{}/{}\tLoss: {}\tEllapsed time: {}".format(epoch + 1, n_epochs, np.mean(loss_values), ellapsed_t))
print('Done')
5. Showing results
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
data_viz_len = 300
viz_embedding = w2v.embed_in.weight.data.cpu()[:data_viz_len]
tsne = TSNE()
embed_tsne = tsne.fit_transform(viz_embedding)
plt.figure(figsize=(16,16))
for w in vocab[:data_viz_len]:
w_id = word2id[w]
plt.scatter(embed_tsne[w_id,0], embed_tsne[w_id,1])
plt.annotate(w, (embed_tsne[w_id,0], embed_tsne[w_id,1]), alpha=0.7)
If you have any questions, please ask them below, I will be happy to answer.